The Missing Layer in Every Supply Chain AI Deployment
How Freight and Customs Teams Turn Fragmented Data Into Agents That Perform Like Your Best Operators

Agentic AI is moving fast in supply chain. The gap between the teams pulling ahead and those falling behind isn't the model they chose - it's the context underneath it.
75% of enterprises aren't seeing AI impact because of context debt: fragmented data, inconsistent formats, and infrastructure built for humans, not agents. In practice, context debt shows up as bloated retrievals, stale data piped to agents, ungrounded outputs, and tool integrations that were never built. In supply chain, every shipment touches dozens of documents, systems, and trading partners - causing this challenge to compound and establish itself deeply.
In this installment of our agentic AI series, we look at why context - and the architecture built to support it - is the foundation of competitive advantage in supply chain, and what it takes to get it right.
Refresher: How Agentic AI Actually Works
An AI agent isn't a chatbot. It's a system built from three things working together: reasoning (a model that can plan a multi-step workflow), tools (the integrations it uses to read documents, query systems, and take action), and memory (the record of what it's done before, and what your operators have decided).
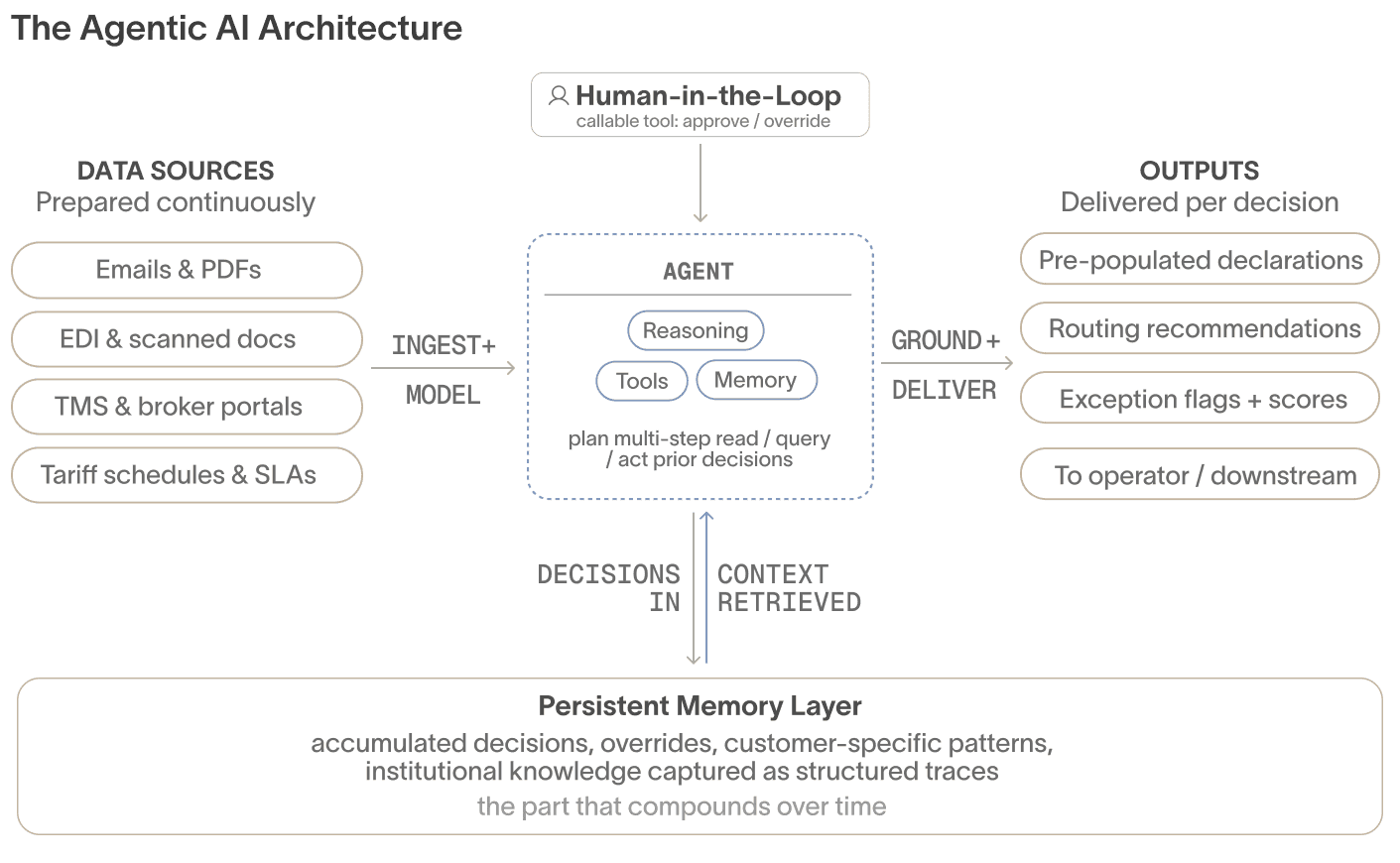
The first installment of this series covers the basics - what agentic AI can and can't do, and how it differs from traditional ML, predictive, and generative AI. Our second blog covered how organizations earn the trust to move agents up the autonomy ladder, from recommending decisions, to approving routine cases, to executing end-to-end within defined parameters.
This installment is about the layer that determines whether any of that works in practice. Reasoning, tools, and memory are necessary, but they're not sufficient on their own. Each one needs the right context - supplied at the right moment - to produce a reliable outcome.
Context engineering is the discipline of getting that right. It's what separates an agent that performs like your best operator from one that confidently makes the wrong call.
What Context Engineering Means In Supply Chain AI
Context engineering treats an agent's attention as a budget, not a bucket. It is the discipline of deciding what an AI agent sees at each step of its reasoning - retrieved from the right source, in the right format, at the right moment - so it can make reliable decisions.
The naive approach is to push everything an agent might need into its context window upfront. In practice, this degrades performance: agents lose focus, miss the relevant signal in the noise, and produce inconsistent outputs. Practitioners call this context rot, and it is one of the most common failure modes in production agent systems.
The alternative is just-in-time retrieval - a concept supply chain leaders already understand intuitively. Rather than pre-loading every customer record, every historical shipment, and every tariff schedule into the agent's working context, the agent retrieves the specific information it needs, when it needs it, through purpose-built tools.
In supply chain, that information is everything an experienced operator carries across six tabs and twenty years on the job - the institutional knowledge that separates a confident decision from a costly mistake. For agents to perform at that level, they need access to:
Shipment history - lane-level patterns, account behaviour, origin-destination performance, and known exceptions on similar movements
Customer priority and SLA terms - who gets escalated first, what's contractually required versus informally expected, and the cost of missing this account's deadlines
Routing constraints and approved carriers - customer-specific carrier approvals, restricted lanes, and certification requirements that vary by trade lane
Associated documents - invoices, BOLs, customs declarations, packing lists, and the semantic relationships between them across the shipment lifecycle
Past human decisions - when your best operator overrode the system, why they did it, and what that means for the next similar shipment. This is the agent's persistent memory layer - the part that compounds over time
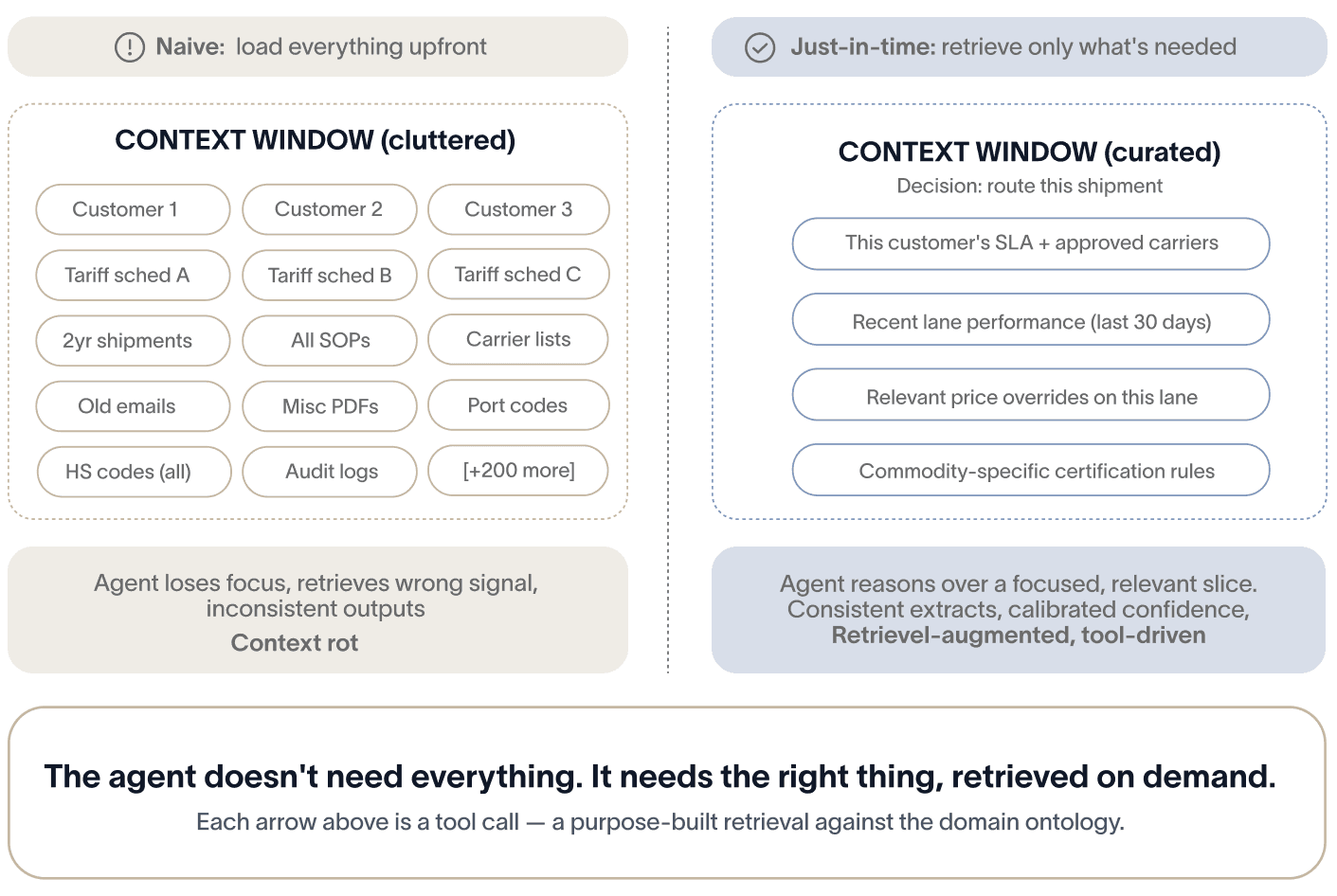
Without the right architecture, agents produce inconsistent results: two identical shipments, two different recommendations, because the retrieval missed the one piece of context that distinguished them.
To engineer context reliably in supply chain, you need a platform that encodes the domain's ontology - the relationships between document types, shipment entities, compliance rules, and customer terms - from the ground up. A general-purpose platform cannot retrofit that. The taxonomy has to be built in.
Example: How Context Changes the Outcome in Freight Operations
WITHOUT CONTEXT
Maya, a freight operations coordinator, receives a booking request for a pharmaceutical shipment from one of her largest accounts. She uses an agentic system without context engineering to propose a routing plan.
The agent has no knowledge that this customer's master agreement restricts pharma shipments to GDP-certified carriers, that the proposed origin-destination lane had three customs delays in the last 30 days, or that Maya's account manager negotiated a tighter SLA at the last quarterly review. The agent returns a routing recommendation that looks reasonable in isolation - cheapest carrier on the lane, standard transit time - but books a non-approved carrier, ignores recent performance signals, and risks breaching an SLA Maya didn't even know had moved.
WITH CONTEXT
With the right context layer, the agent retrieves the customer's approved carrier list, surfaces recent lane disruptions with confidence scores, and flags the SLA risk before proposing routing. Maya gets two ranked options - both compliant with the customer agreement, both scored on on-time probability based on lane history - with the reasoning trail attached. She makes the call in under a minute.
Same booking, materially better outcome. And every routing decision Maya confirms or overrides feeds back into the persistent memory layer - so the next shipment for the same customer, the same lane, or the same commodity is handled with even greater precision.
Why Context Engineering In Supply Chain Is Uniquely Hard
Generic platforms usually fall short for many reasons - and in supply chain, all show up at once.
Document heterogeneity
Thousands of trading partners, zero formatting standards. Off-the-shelf parsers handle clean, structured documents. In supply chain, clean and structured is rarely what arrives - and the edges, where parsers fail, are everywhere.
Unstructured, siloed data
Context is scattered across emails, PDFs, EDI messages, scanned docs, TMS records, and broker portals. Operators bridge these silos manually - a process that can take hours. Agents can do it in seconds, but only when the platform exposes each system through a purpose-built tool the agent can call.
Retrieval at scale
Even when the data is captured, finding the right slice for any given decision is the hard part. Modern systems use semantic search - vector embeddings that match on meaning rather than exact keywords - layered over a domain ontology, so the agent surfaces this customer's HS code history on this lane, not 10,000 vaguely related records.
Institutional knowledge
The most valuable context in any freight or customs operation lives in the decisions experienced operators have made over the years. Most platforms discard it. The right architecture captures it as persistent memory and feeds it back into future retrievals - so agent recommendations improve with every shipment processed.
The competitive edge isn't a better model. It's the data layer that knows which document belongs to which shipment, which customer is on which contract, and what an exception looks like in this specific workflow.
From Raw Data to Reliable Decisions
Context engineering follows four stages - each one transforming how supply chain data is captured, connected, and delivered to agents. Below we show how this works for agents processing a customs entry.
Stage | Purpose | Action | Technique |
Ingest | Collect and tag data from source systems. | A commercial invoice arrives via email - automatically tagged to the correct shipment, customer, and lane. | Structured extraction, entity resolution, document classification. |
Model | Build semantic links between entities and past decisions. | That shipment is connected to the customer's preferred HS codes, routing constraints, and recent human overrides. | Knowledge graph construction, vector indexing over a domain ontology. |
Ground | Supply relevant rules, policies, and context to agents in real time. | Current tariff schedules, tolerance thresholds, and carrier approval lists are fed to the agent before it acts. | Retrieval-augmented generation, just-in-time tool calls, grounding against verifiable sources. |
Deliver | Provide explainable, auditable outputs to users or downstream systems. | A pre-populated customs declaration surfaces with confidence scores, flagged exceptions, and a full reasoning trail - ready for human review. | Schema-constrained outputs, confidence calibration, audit logging. |
Each stage depends on the one before it. Without the right architecture underneath, the chain breaks - and agents act on incomplete context.
The Compounding Advantage
Context engineering redefines what it means to be data-driven - not through volume, but through clarity. Better context produces better decisions; better decisions produce better data; better data produces better context. In supply chain, you need both architecture and discipline - and you need them designed for this domain.
The organizations building this layer now aren't just getting better individual decisions. They're earning the right to move agents up the autonomy staircase we covered in our last installment - from Recommend, to Approve, to Execute - faster than competitors who skip this step. Context maturity is what makes that progression safe. Without it, Stage 3 is reckless. With it, it's inevitable.
That gap compounds. Two years from now, the difference between organizations that invested in context engineering and those that didn't won't just be operational - it will be structural.
This is what Raft is built to provide - an agentic platform purpose-built for supply chain, where context engineering isn't a feature. It's the foundation. And unlike generic platforms that degrade as they scale, Raft is designed to prevent context rot - keeping context clean, current, and domain-specific as your operation grows.
To find out what context-aware AI could do for your operation, get in touch with Raft.


